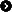I mitt lille eksempel så lagrer jeg filmer, hver film skal ha informasjon om sjanger/kategori og en beskrivelse av filmen.
Eksempel:

Med tanke på at det finnes et gitt antall forskjellige sjangre, så tenker jeg at jeg har en egen tabell med sjangre å velge imellom, slik at jeg unngår å ha repetative data i film-tabellen. Jeg vet at en film kan ha flere sjangre, men i dette eksempelet så sier vi at en film kun kan ha én sjanger. Dette vil altså si at jeg må ha et one-to-many relationship, hvor one=filmer, og many=sjangre.
Dette blir seende slik ut:

Det som er problematisk, er at nå blir det litt bakvendt. Jeg vil jo definere kategorien som tilhører filmen når jeg oppretter en ny film, men nå er det slik at jeg først må definere filmen, så må jeg gå til kategori-tabellen og legge til filmen der etterpå. Dette virker ikke hensiktsmessig?
Dersom jeg gjør det motsatt som dette:

Da kan jeg spesifisere kategorien i foreign key feltet på hver film, men da blir det jo filmen som har many? Hva er det jeg har missforstått her? Databaser er skikkelig forvirrende
Eksempel:
Med tanke på at det finnes et gitt antall forskjellige sjangre, så tenker jeg at jeg har en egen tabell med sjangre å velge imellom, slik at jeg unngår å ha repetative data i film-tabellen. Jeg vet at en film kan ha flere sjangre, men i dette eksempelet så sier vi at en film kun kan ha én sjanger. Dette vil altså si at jeg må ha et one-to-many relationship, hvor one=filmer, og many=sjangre.
Dette blir seende slik ut:
Det som er problematisk, er at nå blir det litt bakvendt. Jeg vil jo definere kategorien som tilhører filmen når jeg oppretter en ny film, men nå er det slik at jeg først må definere filmen, så må jeg gå til kategori-tabellen og legge til filmen der etterpå. Dette virker ikke hensiktsmessig?
Dersom jeg gjør det motsatt som dette:
Da kan jeg spesifisere kategorien i foreign key feltet på hver film, men da blir det jo filmen som har many? Hva er det jeg har missforstått her? Databaser er skikkelig forvirrende


 Jeg har brukt joins, men har trodd at jeg kanskje gjør ting feil med tanke på at det virker så uoptimalt ut, sikkert bare i hodet mitt
Jeg har brukt joins, men har trodd at jeg kanskje gjør ting feil med tanke på at det virker så uoptimalt ut, sikkert bare i hodet mitt