Sitat av
Xasma
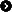
Fra høyre leses binære tall som toerpotenser, så f.eks 1010 i binært blir i konvertering ti titallsystemet: ((2^0)*0)+((2^1)*1)+((2^2)*0)+((2^3)*1) = 10.
Det kan være greit å legge til at det er det samme som skjer med andre tallsystemer, inkludert titallssystemet, eller det desimale tallsystemet som det også kalles. Man summerer sifrene ganget med basen opphøyd i sin posisjon, hvor man begynner å telle fra null.
I titallssystemet, hvor vi i praksis overfører fra titallssystemet til titallssystemet:
5 = 5*10
0
17 = 7*10
0 + 1*10
1
54987 = 7*10
0 + 8*10
1 + 9*10
2 + 4*10
3 + 5*10
4
For å gjøre om binært til titallssystemet:
1010
bin = 0*2
0 + 1*2
1 + 0*2
2 + 1*2
3 = 10.
Det heksadesimale tallsystemet er som alle andre, bare at det har 16 som base. Siden det må være 16 siffer, er sifrene 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E og F. Fremgangsmåten er lik:
7D4A
hex = 10*16
0 + 4*16
1 + 13*16
2 + 7*16
3 = 32074.
Man kan lett bli forvirret av andre tallsystemer om man ikke har erfaring med det. Men det kan hjelpe på forståelsen å visualisere et mekanisk telleapparat av typen man bruker for å telle flypassasjerer og liknende. Hver gang man trykker på knappen, øker tallet med 1. Der har man en rekke hjul, antallet avhenger av hvor mange siffer den har, ikke utseendemessig ulikt snurrehjulene på en vanlig mekanisk kodelås som ofte er på kofferter og hengelåser, eller tellehjulene på gamle kassettspillere.
Først begynner apparatet på 000, om det har tre siffer. Når du trykker på knappen, snurrer det første hjulet en tidels runde rundt, og viser sifferet 1, slik at apparatet nå viser 001. Trykker du igjen går det til 002, også videre. Når du har kommet til det siste sifferet, 9, så vil det som skjer når du trykker være at det første hjulet snurrer over til 0 igjen, men drar med seg neste hjul en tidels runde, slik at det nå står 010. Så går det til 011, 012, 013 også videre. Ved 019 vil neste trykk gjøre at første hjul drar med seg andre hjul over en tidelsrunde til, slik at man kan lese 020. Hjul nummer to vil også dra med seg hjul nummer tre, når det går rundt fra det høyeste til det laveste sifferet, så på 099 vil neste trykk dra første hjul over til laveste siffer, som drar andre hjul over til laveste siffer, som drar tredje hjul over på 1, slik at man får 100 – hundre, altså.
Så er det bare å bytte base. Heksadesimalt er det akkurat det samme som skjer, men der har man sifrene A, B, C, D, E og F i tillegg. Så hjulet har 16 posisjoner (0-F) i stedet for ti (0-9). Når det første hjulet snurrer fra F (desimalt 15) til 0, drar det med seg neste hjul et hakk, og det heksadesimale telleapparatet viser 010 der det desimale telleapparatet viser 016. Neste er 011, så 012 også videre.
Binært, samme prinsipp, bare at der har vi kun to siffer, og ikke ti eller 16. Du begynner å telle, og apparatet går fra 000 til 001. Allerede neste trykk går nederste hjul fra høyeste til laveste siffer, og drar med seg det foran et hakk, så man får 010. Neste trykk gir 011. Deretter drar det første hjulet med seg det andre hjulet som drar med seg det tredje hjulet, og vi får 100. Og sånn fortsetter det videre oppover.
Sist endret av Provo; 16. mai 2018 kl. 15:35.



 )
)