Lagre bøker NB.no
Kanskje ikke helt undergrunn å lagre noe som ligger ute på nettet for alle med norsk IP, men jeg prøver meg.
Er det noen her som kunne hjulpet meg med å lagret et par bøker fra NB.no? Det jeg vil prøve på er å lagre bildene som nettsiden viser. Ser i URL at de ligger fra 0-100 f. eks ved en bok på 100 sider. Sikkert ikke hokkuspokkus å få til dette. Har søkt på forumet, googlet, ja, det meste i et par dager nå. Håper at noen kunne hjelpe meg :) Takk på forhånd. (Fint om vi slipper linker til lovdata her nå :) |
Hei! Jeg lastet ned en del bøker fra nb.no før, men ser nå at de har fått en helt ny nettside og dermed også nytt system for visning av boksidene. Før var sidene lagret som ett enkelt bilde, nå ser det ut som om de ofte er delt opp i to (i hvert fall når man øker kvaliteten/størrelsen på boksiden). Dette gjør metoden min noe utdatert, men jeg kan allikevel dele den med deg.
Du trenger: Firefox, BatchDownload , ReNamer og eventuelt CutePDF Writer eller lignende. Jeg bruker "Sult" av Knut Hamsun som eksempelbok. Bla opp til første side med tekst, i mitt tilfelle blir det siden hvor det kun står "Sult". (Dette fordi det ser ut som om forsiden, baksiden og noen andre "spesialsider" faller utenfor systemet jeg bruker.) På den siden du bladde opp, høyreklikker du og trykker "Kopier bildeadresse". Det skal være et firesifret tall etter no-nb_digibok_[BOKAS ID]_XXXX, for eksempel no-nb_digibok_2009011604050_0001. Da får du noe lignende: Kode:
http://www.nb.no/services/image/resolver?url_ver=geneza&urn=URN:NBN:no-nb_digibok_2009011604050_0001&maxLevel=5&level=2&col=0&row=0&resX=1744&resY=2872&tileWidth=1024&tileHeight=1024Nå lager du på PC-en din en mappe kalt "Sult", og deretter tre undermapper, f.eks. A, B og C. Finn også ut hva som er adressen til siste vanlige side. I vårt tilfelle er det no-nb_digibok_2009011604050_0160. Høyreklikk deretter i Firefox og klikk på "BatchDownload". I feltet til "Base Url" limer du inn den &level=3-adressen vi fant i stad, i dette tilfellet denne. Endre så no-nb_digibok_2009011604050_0001 til no-nb_digibok_2009011604050_000(*), sett "Numbers: From" fra 1 til 9 og sett "Download folder" til Sult\A. Klikk deretter på "Start". Prossessen må deretter gjentas igjen, men nå må 000(*) forandres til 00(*), "Numbers: From" fra 10 til 99 og nedlastningsmappen til Sult\B. Klikk Start. Og jadda, enda en gang: denne gangen med 0(*), tall fra 100 til 160 (altså det vi istad fant ut at var siste side) og mappen til Sult\C. Grunnen til at vi må gjøre dette i tre prosesser er at BatchDownload gjør om 001 i "Numbers: From" til 1. Den skjønner altså ikke at den skal telle 001, 002, 003, istedet for 1, 2 og 3. Om vi ikke hadde lastet ned til tre forskjellige mapper, ville BatchDownload overskrevet de tidligere boksidene den har lastet ned. Dette skjønner du hvorfor om du ser i mappe A, B og C, siden filene får navn 001.jpg, 002.jpg, osv i alle mappene. Nå kan du lukke både BatchDownload og Firefox, for så å starte ReNamer. Dra først filene dine fra mappe A inn i feltet "Drag your files here". Gjør så det samme med filene fra mappe B og deretter C. Klikk "Add", "Strip", huk av for "Digits" og klikk "Add rule". Du får da en feilmelding som sier at flere bilder får samme navn, klikk bare ok da. Trykk på ny på "Add", så på "Serialize" og "Add rule". Trykk så på "Rename". Nå skal filene ha fått forskjellige navn, fra 1.jpg og til og med 160.jpg. Du kan derfor nå klippe ut alle bildene fra A, B og C og lime inn i mappen "Sult", før du sletter de tre tomme mappene. Nå har du for så vidt lagret hele boka, men om du synes det er upraktisk å ha hver side lagret som et bilde, kan du bruke f.eks. Cute PDF Writer til å lage én pdf av alle bildene. Selv om dette ble et nokså langt innlegg, håper jeg du får det til! Hvis ikke er det bare å spørre i vei. Så får vi håpe at noen etter hvert også finner en god måte for å få lastet ned sidene i bedre kvalitet. God lesning! :) |
Takk for meget utfyllende svar! Skal nok lese det én gang til før jeg prøver meg ;)
KP |
Mekket til en downloader til et tidligere prosjet jeg hadde (lage ebøker av en serie som ikke er utgitt digitalt).
Du kan finne den her. Laget i java, og bør kjøre fint på de fleste plattformer. For å bruke denne plotter du inn bokID, fra side, til side (ingen fare om du setter denne for høyt), level og maxlevel. De to sistnevnte finner du i URL'en om du åpner et bilde fra eboken her f.eks brukes maxlevel 5 og level 3. Level og Maxlevel kan være noe krøll å få på plass, zorro hadde en fin beskrivelse hva dette er. Trykk last ned - mappe lages og navngis fra bokID, hvor alle bildene inkl. cover blir lagret. Kan anbefale XnView for å kikke fort over bildene at alle er hele. |
Bok nr. 1 lagret i PDF-format etter Zorros oppskrift! ;)
Takk for det, Lanjelin! Skal ses på! |
Ønsker Level 5 i nbno.jar
Hei,
Har brukt Lanjelins downloader flere ganger med vellykket resultat! Takk for det! Men, jeg opplever at det er behov for bedre kvalitet for å få god lesbarhet av den nedlastede teksten. Opp til Level 4 kommer hver side som ett image, men som Zorro beskriver, er problemet at for høyere Levels blir sidene delt i to eller flere images. Såvidt jeg kan se, gir Level 5 at sidene blir delt i to images for hhv. øvre og nedre halvdel. Level 6 gir fire kvartsider. Level 5 gir mye bedre kvalitet enn Level 4 og er helt OK til mitt formål, men da leverer Lanjelins downloader bare øvre halvside. Da jeg ikke er oppegående på Java, vil jeg med dette spørre om Lanjelin kunne tenke seg å utvide downloaderen til å handtere Level 5 også? Om ikke annet ville det være til stor hjelp om downloaderen kunne levere både øvre og nedre halvdel, så skal jeg vel finne en måte å lime dem sammen på. |
Sitat:
Greide å slette kildekoden, og da det er det andre prosjektet jeg har hatt i java, vegret jeg meg litt for å ta det opp igjen, da det fører til endel lesing for å få til ganske basiske ting. Uansett, fikk dekompilert den gamle downloaderen, og mekket/oppdatert koden, for å implementere en funksjon som du nevner. Har selv ikke vært borti bøker der sidene er delt i to, men kodet på grunnlag av slik du beskriver det. Har derimot fått testet på bøker der sidene er delt i 4 og i 6, og det ser ut til å fungere uten problemer. Da jeg først var i gang, slengte jeg like lett inn en funksjon som setter bildene sammen til ett enkelt, etter hvert som den laster ned de forskjellige delene. Da det er brukt over, kan jeg også bruke Knut Hamsunds Sult som eksempel; med maxLevel 5, Level 5, 4 bilder for hver side, ender en opp med bilder på 1688x2830. Nye filen kan finnes her. :bergenser: |
4 Vedlegg
Lanjelin: Ut i fra hva du skriver, virker det som et meget nyttig kode du har skrevet! Jeg får den dessverre ikke til å fungere på Mac med Mavericks, da det ser slik ut:
http://freak.no/forum/attachment.php...5&d=1399146214 Jeg antar den hvite boksen nederst egentlig ikke skal være der? Har ingen Windows-maskin i nærheten som jeg kan teste på. :) Legger derfor også ut min metode for å laste ned bøker i full kvalitet på, selv om den er nokså rotete og litt tungvind (disclaimer: jeg er kun en hobby-programmerer!). Se vedlegget "nb-download.zip" for filene. Disse må lastes opp på en server som kjører PHP. Videre følger en trinnvis gjennomgang av hvordan man laster ned Hamsuns "Sult". 1) Åpne boka på Nasjonalbiblioteket sine nettsider, og gå til første side du ønsker å laste ned. Høyreklikk deretter og vis bildet. Kopierer bildeadressen. Ved problemer: sjekk at du har huket av på HTML og ikke på Flash-visning av boka! 2) Åpne index.php på serveren din. Du vil da få opp en dialogboks som spør etter bildeadresse; lim inn adressen her. Scale kan bare stå på 100, siden dette egentlig er en funksjon jeg ikke har giddet å verken fjerne/lage ferdig. Om du ikke får opp dialogboksen: sjekk at du har Javascript aktivert i nettleseren! 3) Siden du har limt inn, i vårt tilfelle denne, vil nå vises i best mulig kvalitet - boksiden blir lagret på serveren din som "temp.jpg", og blir overskrevet om du limer inn en ny bildeadresse i dialogboksen på index.php. Trykk deretter på lenken hvor det står "(kode)". Du vil da få opp en kodesnutt lignende denne: Kode:
$colrow_file = "col1row2.php";5) Sjekk nå hva som var sidetallet til den første siden du ville laste ned. OBS: ikke sjekk sidetallet på selve boksida, men den som finnes i URL-adressen - altså: &urn=URN:NBN:no-nb_digibok_2009011604050_XXXX. I vårt eksempel velger jeg 0003 og 0159 som start og slutt. Forside- og bakside-cover bruker et annet system, så velg første og siste "ordentlig" side. 6) Rediger start- og sluttverdi på loopen, slik at det i vårt tilfelle blir slik: Kode:
$loop=3; // start sidetallOm du skulle klare å avbryte loop.php mens den laster, kan du bare endre startverdien på loopen ( $loop=XX; ) til det siste filnavnet du har i "output"-mappa. 8) Når du ser at siste side ligger i "output" (i vårt tilfellle "0159.jpg"), kan du kopiere alle bildene over på din maskin. Jeg pleier dog å gjøre dette underveis/eventuelt laste ned boka i etapper, men dette er fordi jeg ikke har så altfor mye ledig plass på serveren min for tida. Når det er gjort, kan du slette alle bildene fra "output"-mappa på serveren. 9) For å laste ned for- og bakside av boka: Åpne forsiden av boka på Nasjonalbiblioteket sine sider, og kopierer bildeadressen. (Sidetallet er som oftest "C1"). Lim inn i dialogboksen på index.php, og last ned bildet som blir generert. Gjør det samme med baksiden av boka (som oftest er sidetallet "C3"). Du skal nå ha fått lastet ned alle sidene. Du kan eventuelt slå de sammen til en pdf, noe jeg pleier å bruke Automator (på Mac) til (guide). Legg da merke til at for-/bakside ikke har samme dimensjoner som resten av bildene; du trenger ikke å beskjære dem slik at de får samme dimensjon som resten av boka, men jeg synes det ser mye penere ut når det er gjort! Du kan også bruke Automator til å skalere bildene dine, om du vil redusere filstørrelsen (guide). I mine øyne kan man ofte redusere bildestørrelsen en god del uten at lesbarheten blir merkbart dårligere. Se de første sidene av endelig resultat her (uskalert). Håper du får det til - bøker til folket! Hvis ikke er det bare å spørre, eller bruke Lanjelin sitt noe mer brukervennlige program. :) |
Sitat:
Problemet er med måten jeg har bygget opp UI'en på, da endring av bredde påvirker plasseringen til elementene. Er langt ifra erfaren med java, kan vel på godt norsk kalles en noob. Har satt opp instillingene for bredden, så om du laster den ned igjen, havnet forhåpentligvis elementene noenlundes på rett plass. Har dessuten rettet opp i en feil for lasting av sider med to bilder, samt lagt til støtte for 8. Slik ser det ut for meg. http://i.imgur.com/aPHQaug.png |
Hei!
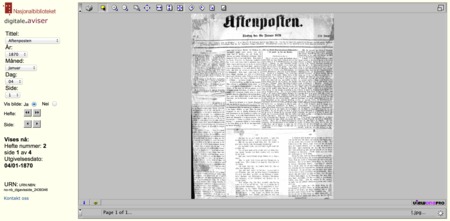
Jeg bare lurer, men går det ann å "lure" seg rundt sperren som gjør at stoffet jeg har lyst til å se på nb.no kun er tilgjengelig i norske biblioteker? Gjelder forøvrig Aftenposten fra perioden under krigen. |
Sitat:
En tur innom Google (hvor site:nb.no er en flott funksjon!), avslørte denne lenken. Derfra fant jeg fram til en Java-applet hvor man kunne lese avisene: https://imma.gr//58785.jpg Eneste problemet nå, er at dropdown-menyen på venstre side ikke går lenger fram til år 1908 - men det stopper da ikke oss! Ved å se på URL-adressen, kan du se hvordan systemet er bygget opp: Kode:
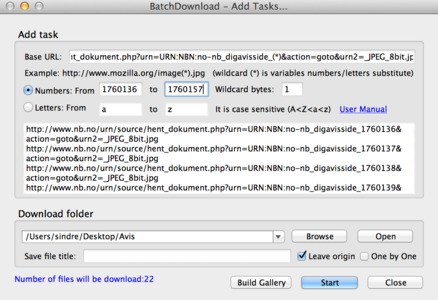
Her er siste avisa dropdown-menyen viser (31. des 1908):Et par kommentarer angående direktelenker. Om du ser på adressen, vil du oppdage "URN:NBN:no-nb_digavisside_1760136". Ved å øke/minske URN:NBN:no-nb_digavisside_XXXXXXX (med én) vil du gå til neste/forrige side. Om du i en URL-adresse finner &vis_startnummer=XXXXXXX, kan du bruke dette tallet til å finne direktelenken til riktig avis. Eventuelt kan du høyreklikke på en avisside -> "Image" -> "Image Properties" og finne adressen der. Dette kan være meget nyttig om du ønsker å laste ned en hel avis/årgang - du kan da bruke for eksempel Firefox + BatchDownload: https://imma.gr//58786.jpg Etter dette kan du jo slå bildene sammen til en pdf, og du vil få noe lignende dette eller dette. Jeg anbefaler i tillegg å prøve deg litt fram med å endre på de andre verdiene du får oppgitt i URL-feltet. Eksempelvis forteller &tittel Java-appleten hvilken avis den skal vise; siden du nevnte Aftenposten brukte jeg den som eksempel (med &tittel=URN:NBN:no-nb_digavishefte_5). Denne kan du for eksempel bytte ut med URN:NBN:no-nb_digavishefte_27 (som er VG). Det er lærerikt å prøve seg fram! Håper du får det til, gamle aviser er spennende saker! :) |
Takk for svaret! Det var til stor hjelp :)
|
her er noen script som kan laste ned ei liste med bøker fra nb og lage pdf-bøker av dem. les 00readme.txt der for mer info. takker for hjelp fra dere folka ovanfor her i tråden.
/jo Link til kode http://www101.zippyshare.com/v/nSnZWvTs/file.html |
Jeg prøvde den snutten din, Jonny2, men ingenting fungerte. Er det noen programmer jeg må ha på pc'n for å få det til å fungere?
|
hei
jeg har brukt XAMPP (v5.6.24) under windows. installér XAMPP så har du Apache og PHP og kan kjøre scripta på pc'en via http://localhost/nb-dl/ (Legg script-mappa nb-dl inn i xampp\htdocs\. i mitt tilfelle installerte jeg XAMPP til C:\xampp, dermed ligger scripta slik: C:\xampp\htdocs\nb-dl\ ) Deretter følger du det som står i 00readme.txt. husk at bookids.txt er lista med bøker du vil laste ned (én bok-id per linje). du kan lime inn id'er der manuelt, eller bruke html-filene og klikke "Last ned" ved en boktittel for at bok-id'en skal legges til bookids.txt. Når du har en eller flere linjer i bookids.txt så kan du kjøre nbno7.php (som er den siste versjonen). lykke til da, prøv deg fram ved å lese 00readme.txt -j |
er helt ubruklig til it realterte ting men hvor finner jeg bok id! på nb ?
|
hei
når du åpner ei bok i nb.no så ligger iden til boka nederst til venstre på sida som del av "varig lenke": f.eks. åpne boka http://www.nb.no/nbsok/nb/375b21b8b2...e2c4?index=3#0 der nederst ligger "varig lenke": http://urn.nb.no/URN:NBN:no-nb_digibok_2008022704024 bokid er siste del av den adressa (det som kommer etter digibok_), altså: 2008022704024 er bokid. hvis du laster ned php-scripta på http://www101.zippyshare.com/v/nSnZWvTs/file.html og legger det på en php-server så kan du søke etter bøker med search.php og legge til bokid med å trykke på en knapp, det er enklere. hilsen jonny |
Da har jeg prøvd og faila hardt :( trenger mer hjelp as
|
jeg foreslår du prøve Lanjelins "nb.no nedlaster", over i tråden, den funker bra og du trenger ikke mye it kjennskap for å bruke den.
|
Sitat:
Jeg har en liten bønn... Kunne du tenke deg å lage en revisjon, hvor programmet støtter sider som er delt inn i flere biter enn 8? Ganske mange bøker/publikasjoner på NB er nå lagt ut i 12 deler pr. side, om man vil ha bra kvalitet. Sikkert andre varianter også - kanskje flere enn 12 til og med. Jeg har ikke forsket på dette. Et eksempel: http://www.nb.no/nbsok/nb/6e0a629ed5...ital?lang=no#0 Jeg er helt blank på java, og klarer ikke gjøre dette selv. Men tipper det er nokså lett for dere som kan det! |
@Lanjelin
Har brukt java programmet ditt til stor fryd i flere år, men nå har det problemer med sider som består av flere bilder på x aksen. Hadde satt stor pris på om du kunne sett på det og evt oppdatert om det finnes en løsning! |
Jeg fikk ikke nbno3.jar fra lanjelin til å funke i det hele tatt. Virker som at URL-formatet har endret seg, og den fant ingen sider...?
...men jeg fikk python-utgaven til å fungere (etter litt feilsøking, en kjapp oppskrift med dependencies hadde gjort seg - omså bare som kommentar øverst i koden) etter hvert. Men støtte på samme problemet som kadiro - boksidene ble kuttet på høyresiden. Se f.eks https://gist.github.com/Lanjelin/3d7...59e7a4a436e046 Forresten er det id'en i "Varig lenke"-feltet helt nederst som må bruikes. |
Sitat:
|
Sitat:
Virket bra når jeg installerte Python 2.7.13 med Pillow og wxPython (+ da selvsagt nbno.py) Kjører Windows 10, og brukte: - nbno.py - python-2.7.13.msi - Pillow-2.2.1.win32-py2.7.exe - wxPython3.0-win32-3.0.2.0-py27.exe Husk å huke av for at Python skal oppdatere Path. Fikk også noen warnings fordi jeg ikke kjørte som admin, og den da ikke fikk oppdatert Registry riktig. Ignorerte disse, og dette ser ikke ut til å gjøre noe. Tenkte nå å teste en PDF-creator ala CutePDF. Tusen takk så langt! |
NB.no har nå gått over til https og derfor vil ikke php-scriptet til jonny2 fungere rett ut av boksen.
To små endringer i filen nbno7.php må til: 1. endre alle http til https (tre plasser, ca linje 80, 95 og 135) 2. legge til følgende to linjer etter linje 51 ($timeout = 15) curl_setopt($ch,CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch,CURLOPT_SSL_VERIFYPEER, false); Takk for scriptene, jonny2! |
Endringene gullien viser til over funker ikke per dags dato.
Er det andre som kan få jonny2s metode til å funke igjen? Får følgende meldinger: Warning: fopen(hang.txt): failed to open stream: Permission denied in /opt/lampp/htdocs/nb-dl/nbno7.php on line 70 laster ned bok xxxxxxxxxxxxxx... Warning: get_headers(): php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution in /opt/lampp/htdocs/nb-dl/nbno7.php on line 83 Warning: get_headers(https://www.nb.no/services/image/res...eHeight=1024): failed to open stream: php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution in /opt/lampp/htdocs/nb-dl/nbno7.php on line 83 Warning: get_headers(): php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution in /opt/lampp/htdocs/nb-dl/nbno7.php on line 98 Warning: get_headers(https://www.nb.no/services/image/res...eHeight=1024): failed to open stream: php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution in /opt/lampp/htdocs/nb-dl/nbno7.php on line 98 henter cover 1... Warning: get_headers(): php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution in /opt/lampp/htdocs/nb-dl/nbno7.php on line 138 Warning: get_headers(https://www.nb.no/services/image/res...eHeight=1024): failed to open stream: php_network_getaddresses: getaddrinfo failed: Temporary failure in name resolution in /opt/lampp/htdocs/nb-dl/nbno7.php on line 138 henter side 0001... Warning: rename(tmpbooks/xxxxxxxxxxxxx,trash/xxxxxxxxxxxxx-rnd-195): No such file or directory in /opt/lampp/htdocs/nb-dl/nbno7.php on line 156 Warning: fputs() expects parameter 1 to be resource, boolean given in /opt/lampp/htdocs/nb-dl/nbno7.php on line 157 boka hang seg opp OK Warning: fclose() expects parameter 1 to be resource, boolean given in /opt/lampp/htdocs/nb-dl/nbno7.php on line 184 Noen idéer? Satt meg ned, med litt mer tålmodighet, og prøvde Lanjelin sin python løsning. So far, so good! Det laster ned. Gjorde som de andre: wxPython og Pillow, på Mac-en. Det ser ut til å funke som bare det! Takk til Jonny2 for svarene sine, og takk til Lanjelin for flott løsning. Fikk lyst til å lære meg Python. Sommeren ser ut til å bli Python for meg! |
Hvordan er det med dette og den nye sida? Har jeg noen som helst sjangse for å få lest bøkene fra NB på min Kindle?
|
I går lastet jeg ned en bok med Lanjelin sin python-kode, og den kom uten høyre sida av bildet.
Nå oppdaterte jeg scripten med den han lenker til nederst i sine innlegg og kjørte en test. Den kutter fremdeles høyre siden av sida, men denne gangen var hele teksten med. Jeg laster den ned på nytt, og krysser fingrene. En oppdatering av koden for å behandle sider delt i flere bilder hadde vært ypperlig, men det kan vi ikke kreve. Og oppdateringen mislyktes. Den fortsette å kutte høyre siden av sida, og med det, deler av teksten. Kommer det noen oppdatering for det? |
takker for endringene gullien! scripta funger bra med https nå :cool: (bruker windows og xammp-server).
re:vanda og andre med feilmeldinger: som sagt i pm, tror det kan være noe med server-oppsettet som gir feilmeldinger. prøv å bruk nb.no sin ip adresse istedenfor navn (endre https://nb.no/ til https://158.39.129.53/ i scriptet). her er noen andre forslag: https://stackoverflow.com/questions/...tting-informat |
Tusen takk jonny2.
Jeg har nå testet koden på en windows maskin og det funket utmerket med endringene fra gullien. |
Takk til jonny2 for et script jeg fikk til å funke helt fint ved å følge beskrivelsen - og takk til gullien for den nødvendige oppdateringen. Ut fra mine begrensede kunnskaper om php og servere hadde jeg nesten ikke ventet at jeg skulle få det til. Takket være den nøyaktige oppskriften klarte jeg det!
Jeg lurte på - er det en enkel måte å modifisere scriptet slik at det laster ned bøker i max kvalitet? |
slik scriptet er nå kan du laste ned en bedre kvalitet enkelt ved å endre linje 18 fra $level = 3 til $level = 4. hvis bøkene har vanlig format funker det uten problem.
for å gjøre scriptet mer fleksibelt, og laste ned max kvalitet ($level = 5) må scriptet endres mer. pseudo-kode: - gitt $level, finn ut hvor mange bilder som inngår i ei side (rekker og kolonner) slik som linje 80-90 idag sjekker om det er 2 kolonner eller ikke. - last ned rekker og kolonner og sett sammen bildet, endre funksjonen merge linje 25. skal prøve å endre på scriptet asap. men som sagt, bare endre til $level = 4, skal gå fint og gi høyere kvalitet. j2 |
Hadde sikkert ikke vært veldig dumt om noen laget et fullverdig repository av dette, men da burde man helst hatt Lanjelin's velsignelse. :)
|
jeg har endra på scriptet som laster ned bøker slik at du kan sette kvalitet/størrelse.
her er fila nbno9.php (som erstatter tidligere versjoner 1-8). http://www49.zippyshare.com/v/UYeeDfzF/file.html kvaliteten settes i fila på linje 25. 3: God, lesbar kvalitet (en normal bokside blir ca. 100 kb, dvs. bok på 150 sider blir ca. 15 mb). 4: Bedre kvalitet (ca. 250 kb/bokside, bok ca. 37 mb). 5: Er max størrelse/kvalitet (ca. 500 kb/bokside, bok ca. 75 mb). resten av filene i systemet er som før, og kan lastes ned på http://www101.zippyshare.com/v/nSnZWvTs/file.html |
Fantastisk, jonny2! Takker så mye for dette. Tenker mange andre også blir glade for denne muligheten.
|
Er veldig, veldig interessert i å få dette til å funke, har lastet ned jonny2's filer. Men min Mac forstår ikke hvordan den kan kjøre php filene. Er fullstendig Python begynner, eller enda mindre. Kan noen hjelpe litt videre?
|
Sitat:
https://www.apachefriends.org/index.html les videre der og se om du får det til. jeg har windows selv og vet ikke altfor mye om mac og hvordan xampp oppfører seg der. |
Hei og takk for tips. Har installert xampp, og får nå(?) kjørt php i min terminal, men jeg kommer likevel ikke videre. Helt konkret vil jeg laste ned denne boka (i nb_liste_Michaelsen, Aslaug Groven.html):
Moen, Niels | Slekter og gårder i Brøttum sogn | 2012052224008 | 1965 | | Brøttumsboka | http://urn.nb.no/URN:NBN:no-nb_digibok_2012052224008 Web Last ned Har forstått det slik at 2012052224008 er bok_ID. 'Last ned' gir meg feilmelding i Safari web-browser'n ('can't connect to the server, "localhost/nb-dl/leggtilbok.php?id=2012052224008" because Safari can't connect to the server "localhost".) Så jeg kopierer 2012052224008 manuelt inn i fila bookids.txt. Deretter, i Terminal: 'php nbno9.php' Dette gir følgende resultat: laster ned bok 2012052224008...<br>sidene i boka er ikke delt.<br>henter cover 1...<br> Warning: rename(tmpbooks/2012052224008/col0row0.jpg,tmpbooks/2012052224008/colrow0.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 42 Warning: rename(tmpbooks/2012052224008/colrow0.jpg,tmpbooks/2012052224008/colrow.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 48 Warning: rename(tmpbooks/2012052224008/colrow.jpg,tmpbooks/2012052224008/cover1.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 180 henter cover 2...<br> Warning: rename(tmpbooks/2012052224008/col0row0.jpg,tmpbooks/2012052224008/colrow0.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 42 Warning: rename(tmpbooks/2012052224008/colrow0.jpg,tmpbooks/2012052224008/colrow.jpg): No such file or directory in /[path]/Downloads/Nasjonalbiblioteket/nb-dl/nbno9.php on line 48 Warning: rename(tmpbooks/2012052224008/colrow.jpg,tmpbooks/2012052224008/cover2.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 180 henter cover 3...<br> Warning: rename(tmpbooks/2012052224008/col0row0.jpg,tmpbooks/2012052224008/colrow0.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 42 Warning: rename(tmpbooks/2012052224008/colrow0.jpg,tmpbooks/2012052224008/colrow.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 48 Warning: rename(tmpbooks/2012052224008/colrow.jpg,tmpbooks/2012052224008/cover3.jpg): No such file or directory in /[path]/nb-dl/nbno9.php on line 180 henter side 0001...<br>fant ikke boka<br>OK<p>MacBook-Pro:nb-dl aaa$ ... Kan du hjelpe videre? Jeg befinner meg forøvrig altså i utlandet dersom det skulle ha noe å si...? |
Sitat:
|
Forøvrig er xampp helt unødvendig for å kjøre php, og derfor noe man helst bør holde seg unna. OS X har PHP innebygd.
|
anthon, ser ut som du er godt igang.
feilmeldingene kommer antaglig av at nb.no krever norsk ip så sidene har ikke blitt nedlasta. sjekk også at du har filstrukturen som i readme-fila (tmpbooks/, books/, donebooks/, trash/) dersom du får flere feilmeldinger. jeg har brukt tunnelbear vpn fra utlandet mot nb.no (500mb gratis/mnd). visste forøvrig ikke at OS X har PHP innebygd... |
Hurra!! Tunnelbear kjente jeg ikke til. Tusen takk. Scriptet funker også!
|
Tenkte bare å slenge inn denne angående Tunnelbear.
YouTube-kanalene Techquickie / Linus Tech Tips, som formodentlig har et snev av integritet i ryggraden, har bestemt seg for å ikke lengre la seg sponse av Tunnelbear. Litt mer utgreiing om det kan dere se her: https://www.youtube.com/watch?v=RNG4-9BqUIQ Har også lest litt diverse artikler om situasjonen på nett. Har ikke sett veldig mange som er veldig positive til det. |
Noen tråder kan det lønne seg å abbonere på ser jeg, har forøvrig fått etpar PM'er, og innsett jeg måtte gjøre noe med pythonscriptet mitt.
Det har jeg nå fått gjort, og det ligger nå hostet her på GitHub. Har skrevet alt på nytt, droppet fancy UI for kommandolinje og bedre funksjonalitet. Det spiser alt jeg har kommet over av bøker, inklusive Tolkiens Brev fra Julenissen som er på whooping 20 bilder per side. Som tidligere kreves Python 2.7 for å kjøre dette, samt en må legge til pillow. Pillow legges til ved å kjøre pip install pillow eller easy_install pillow etter python er installert (Husk å få med at Python skal oppdatere Path). For å kjøre scriptet er kommandoen rimelig enkel, det eneste påkrevde argumentet er bokID (som finnes ved å trykke del for så å kopiere tallrekken etter digibok_ i lenken som dukker opp). Kode:
bruk: nbno.py [-h] [--id <bokID>] [--start <int>] [--stop <int>] |
Jeg har ingen forkunnskaper om koding, men det er ei bok jeg virkelig gjerne skulle ha lasta ned, så here we go:
Alle guider til installasjon av pillow forsikrer at det skal være så enkelt, men jeg får bare ikke hodet mitt rundt dette. Hva skal jeg laste ned, hvor skal jeg legge nedlastinga, hvor skal jeg kjøre inn kommandoene? Og hvor oppdaterer jeg Path i Python? Takknemlig for all hjelp til en novise, her... |
Det er vel som med det meste; det er lett når en har noenlundes peiling på hva en gjør.
Skal forsøke å skrive en lett guide, sitter selv på Mac, men antar du kanskje er på Windows? Det første du gjøer er på gå til python.org/downloads/ og laster ned Python 2.7.x. Kjør denne filen, klikk deg gjennom de første to vinduene med spørsmål, på Customize vinduet må du sørge for at 'pip' og 'Add python.exe to Path' er valg (egentlig kan bare alt være med). Trykk neste, og fullfør installasjonen. Deretter for å bekrefte at alt er installert skikkelig, åpner du kommandolinjen ved å trykke Windowstast+R, skrive cmd, og trykke enter. Skriv inn python --version, og da bør den spytte ut 'Python 2.7.14' (eller nyeste versjon). For å installere pillow, skriver du da videre i kommandolinjen, 'pip install pillow', og det bør spytte ut 'Successfully installed pillow-5.1.0' Deretter stikker du inn på GitHub-siden scriptet ligger på, trykker på 'Clone or download' på høyre siden, og igjen 'Download ZIP'. Pakk ut denne på valgfritt sted, åpne mappen filene ligger i, hold inne 'Shift' mens du høyreklikker inne i mappen, trykk 'Åpne kommandolinje her' (mener det er skrevet slik). Da skal alt være klart for å laste ned en bok, alt en mangler er bokID. BokID finnes ved å gå inn på ønsket bok på nb.no, trykke på 'Referanse' oppe til høyre, og kopiere tallrekken som står oppgitt etter _digibok_ Gå tilbake til kommandovinduet og skriv følgende python nbno.py --id 2007091701011 Scriptet vil kjøre, lage en ny mappe kalt '2007091701011', og fortløpende legge inn cover og bilder (her til boka Den lille røde høna). Det gir tilbakemelding når det er ferdig. Om du ønsker lavere oppløsning, slenger du på en --level 4 (eller 3) etter bokID'en i kommandolinjen, ev. --start 5 --stop 10 for å kun laste ned side 5 til side 10 (pluss cover). Lykke til. |
Tusen, tusen takk!!! Det funker som en drøm! Takk igjen :-)
|
Sitat:
Om det er noen som vet/ gjetter hvordan begrensede bøker og aviser fungerer? Hvordan begrenser de? 1. Tror du bøkene ligger på internett, eller kun lokalt på bibliotekene? 2. Har de en iprange kun åpen for bibliotene? 3. Er de krypterte? 4. Ligger de egentlig helt åpne på internettet, men under et annet subdomene eller noe? Hadde vært fristende å dratt til et slikt bibliotek å sjekke hva URL-en egentlig er der. |
Lanjelin viss du vil ha en Python 3.6 version i Repo ditt.
Skrevet rask om med hjelp av noen verktøy,også litt nærmere PEP-8 ;). Jeg trenges ikke og nevnes viss du bruker koden i Repo. SPOILER ALERT! Vis spoiler Kode:
# nbno_3.py |
Sitat:
En kjører det likt som ved bøker, men slenger på en ekstra --avis Fremgangsmetoden for ID er lik som for bøker, men på avis er den noe lengre, for eksempelet ditt er ID som må brukes alt etter digiavis_, dermed arbeiderbladetoslo_null_null_19621224_77_299_1 Vær også oppmerksom på at det bruker noe lengre tid på å kjøre, da sidene er satt sammen av flere bilder. Denne består av 54 bilder per side (ved level/maxLevel 5/5). Sitat:
Har ikke beveget meg så mye over på python 3.6, og har ikke satt opp maskinen for det heller. Om jeg får kjørt begge parallellt/problemfritt på Mac'en, er det mulig jeg legger det til! Kodingen min består vel i utgangspunktet av 50% bruk av google, om jeg må legge til litt til for å holde vedlike en 3.6 versjon, bør gå greit. |
| Alle tidspunkt er GMT +2. Klokken er nå 21:59. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}