
Hei!
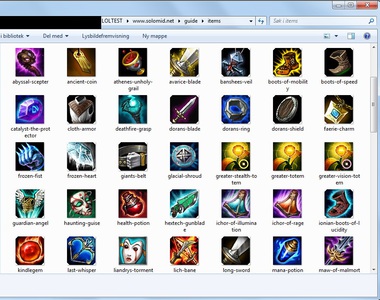
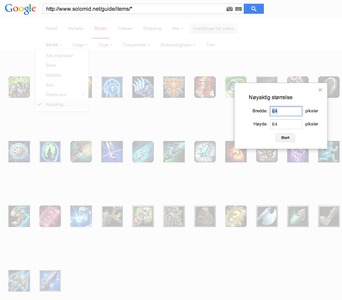
Hvordan kan jeg laste ned alle bilder fra en nettside,eller mer bestemt, en mappe på en nettside?
www.example.com/image/images/
er et eksempel på det jeg vil ha ned. Altså, i en mappe på en side.
Alt jeg vet er at det er en index.html fil der også, så jeg får ikke sett den "index of/" tingen osv.
Hvordan kan jeg laste ned alle bilder fra en nettside,eller mer bestemt, en mappe på en nettside?
www.example.com/image/images/
er et eksempel på det jeg vil ha ned. Altså, i en mappe på en side.
Alt jeg vet er at det er en index.html fil der også, så jeg får ikke sett den "index of/" tingen osv.
Sist endret av Erlendman; 16. februar 2014 kl. 09:04.

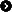




 )
)
{kind=link}
{kind=link}
{kind=link}